Seaborn
Inhalt
Seaborn¶
seaborn eignet sich gut für die Methode Visual Analytics. Visual Analytics zielt auf die Fähigkeit des Menschen, schnell Muster und Trends visuell zu erfassen. Es hat sich zu einem eignen Feld in der Datenanalyse entwickelt und besitzt mittlerweile auch eine umfangreiche Literatur.
seaborn Tutorials finden sich unter https://seaborn.pydata.org/tutorial.html und auch die Gallery https://seaborn.pydata.org/examples/index.html erleichtert den Einstieg.
Wir werden hier nur ein paar der möglichen Diagramme besprechen. Eine vollständige Liste findet sich unter https://seaborn.pydata.org/api.html.
Einführung mit IRIS¶
Wir wollen die Python-Bibliothek seaborn kennenlernen. Dazu nutzen wir wieder den Iris Datensatz.
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(color_codes=True)
Mit seaborn wird der Iris Datensatz mit ausgeliefert und kann leicht geladen werden. Wir erhalten einen pandas Datenframe.
iris_df = sns.load_dataset('iris')
iris_df
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
150 rows × 5 columns
Wir sehen also 150 Beispiele mit 5 Spalten. Wie viele Arten es in diesem Datensatz gibt ist aber noch unklar.
Die pandas Methode unique liefert uns die Anwort.
iris_df['species'].unique()
array(['setosa', 'versicolor', 'virginica'], dtype=object)
len(iris_df['species'].unique())
3
Nach dem wir nun wissen, dass es 3 Klassen gibt wollen wir noch wissen ob der Datensatz ausgewogen (balanced) ist, d.h. ob für jede Klasse annähernd die gleiche Anzahl von Beispielen enthalten sind.
Mit der pandas Methode value_counts() erhalten wir diese Info.
iris_df['species'].value_counts()
setosa 50
versicolor 50
virginica 50
Name: species, dtype: int64
Das Datenframe enthält also 150 Beispiele mit 5 Spalten. 4 dieser Spalten beinhalten reale Zahlen und 1 Spalte kategorische Daten.
Die Kategorische Spalte unterscheidet 3 Unterarten einer Blumenart
Iris-setosa (\(n_{set}=50\))
Iris-versicolor (\(n_{ver}=50\))
Iris-virginica (\(n_{vir}=50\))
Die 4 Merkmale beschreiben die Blätter einer Blumenart:
sepal length in cm
sepal width in cm
petal length in cm
petal width in cm
Die Abbildung zeigt diesen Datensatz nochmals in der Form von Bildern.

Abb. 2 Iris Datensatz, 3 Klassen (Kategorien), 4 Merkmale¶
Tipp
Eine Aufgabe wäre nun mit Hilfe der 4 Merkmalen die Klasse der Blumen zu bestimmen. Im maschinellen Lernen spricht hier von einer Klassifizierung.
Wir wollen aber hier einen anderen Aspekt der Datenanalyse besprechen. Oft ist es hilfreich die Daten zuerst visuell zu inspizieren um ein Gefühl für den Datensatz zu bekommen. Dieses Vorgehen ist insbesondere für kleiner Datensätze empfohlen, hat aber sicher auch Grenzen. Zum Beispiel erscheint eine visuelle Inspektion von Datensätzen mit Millionen Merkmalen wenig aussichtsreich.
Seaborn Diagramme¶
pairplot() and PairGrid¶
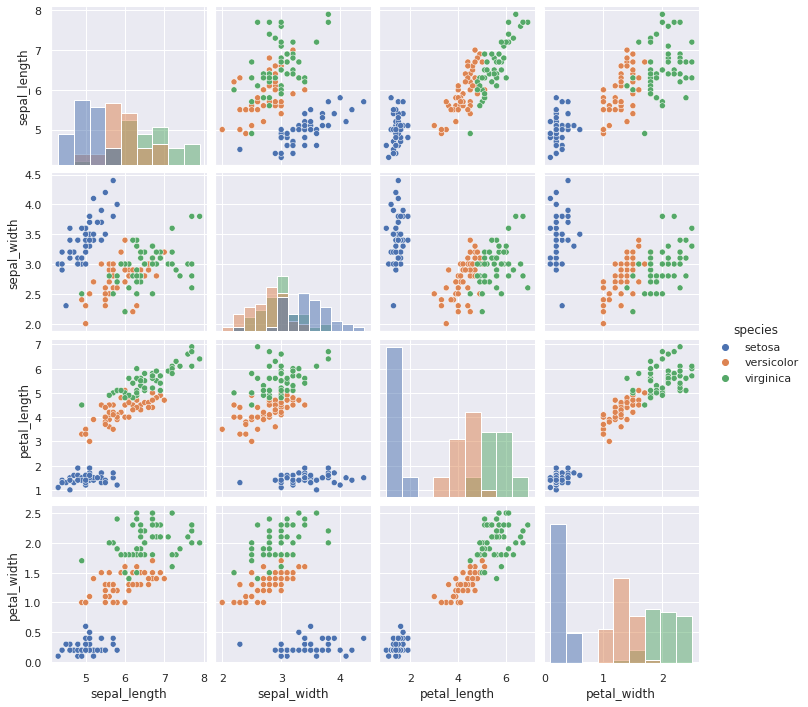
Eine sehr hilfreiche Methode für kategoriale Datensätze ist mit pairplot() gegeben. Dieser erzeugt für jede Paarung scatterplot()-Diagramme und in der Diagonalen histplot()-Diagramme.
sns.pairplot(iris_df)
<seaborn.axisgrid.PairGrid at 0x7f739827c100>
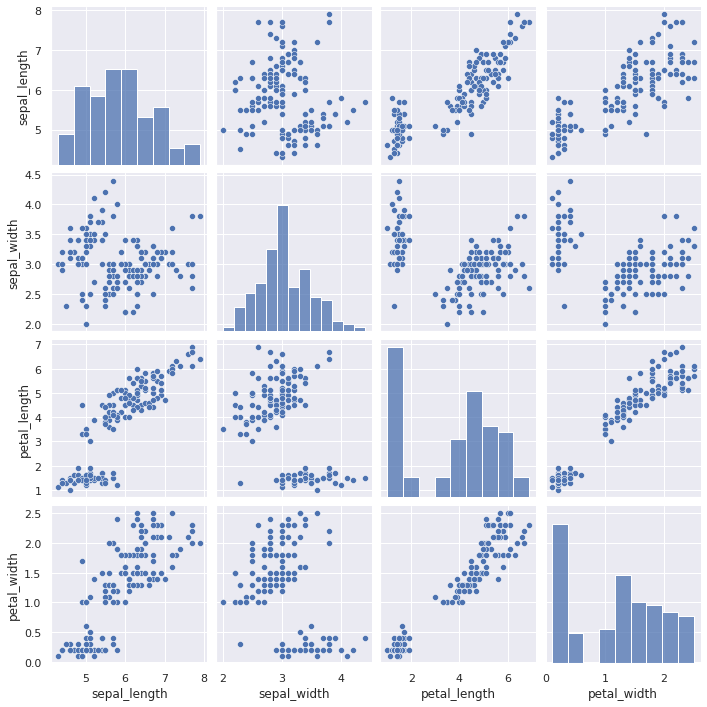
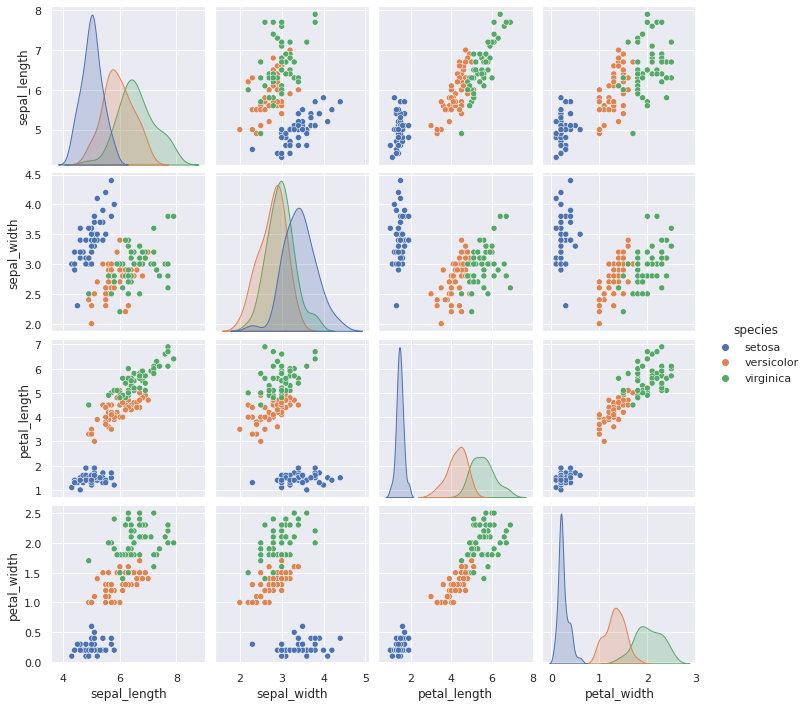
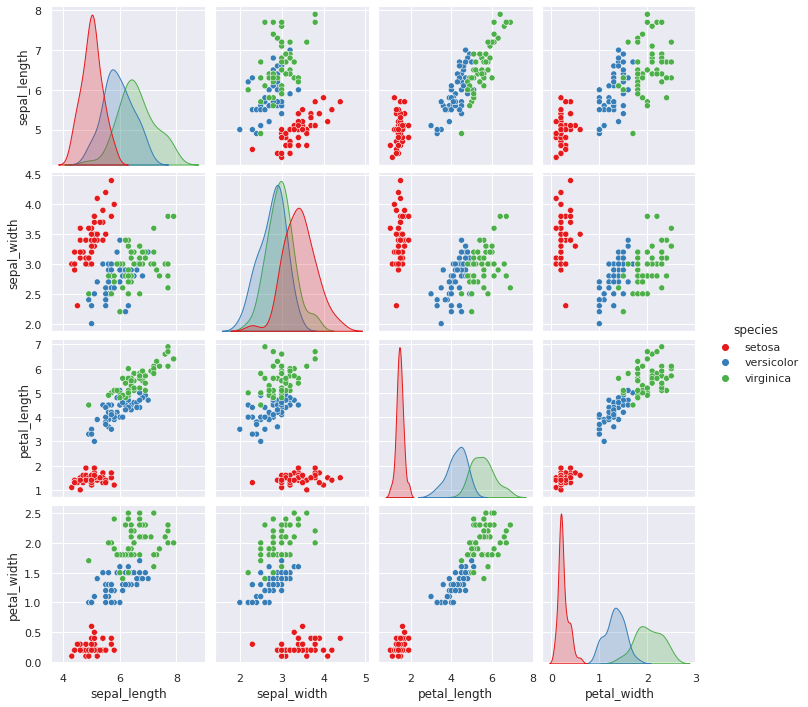
Besser ist aber die Kategorien in den Diagrammen mit auszuweisen. Eine semantische Zuordnung kann mit der hue Variable erreicht werden.
Dadurch ändert sich aber auch die Diagonale, welche nun eine Kerneldichteschätzung (KDE) zeigt. Die KDE zeigt wie sich die Kategorien in den Merkmalen überlaben. Die Scatterplots zeigen wie man Kombination von Merkmalen eine Unterscheidung ermöglichen würden.
sns.pairplot(iris_df, hue="species")
<seaborn.axisgrid.PairGrid at 0x7f7385c99eb0>
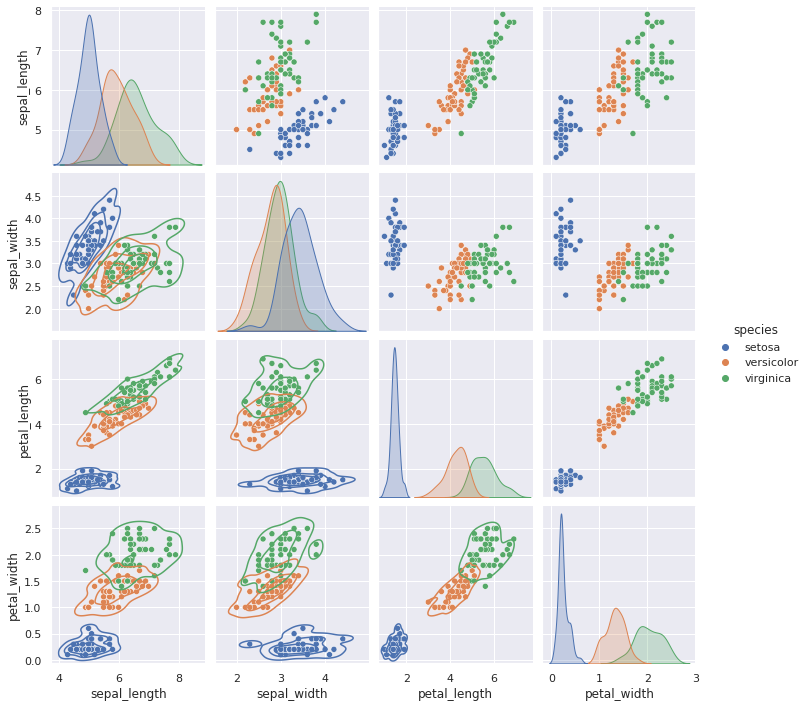
Wir können KDE über die Scatterplots legen.
g = sns.pairplot(iris_df, hue="species")
g.map_lower(sns.kdeplot, levels=4, color=".2")
<seaborn.axisgrid.PairGrid at 0x7f7385baf340>
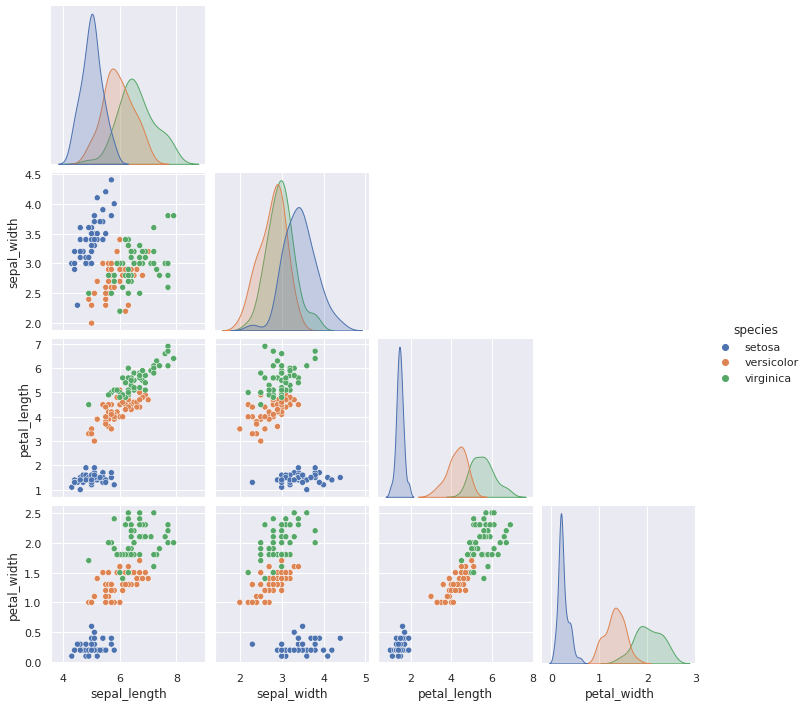
Wir können ein „Ecken“-Diagramm erzwingen.
sns.pairplot(iris_df, hue="species", corner=True)
<seaborn.axisgrid.PairGrid at 0x7f738cc7ed60>
Die Diagonale kann aber wieder auf ein Histogramm geändert werden. Dazu benutzen wir den Parameter diag_kind="hist".
sns.pairplot(iris_df, hue="species", diag_kind="hist")
<seaborn.axisgrid.PairGrid at 0x7f738cc56ac0>
Auch die farbliche Codierung kann leicht verändert werden. Mit dem Parameter palette können wir verschiedene Farbpaletten verwenden.
sns.pairplot(iris_df, hue="species", palette="Set1")
<seaborn.axisgrid.PairGrid at 0x7f7387e7da30>
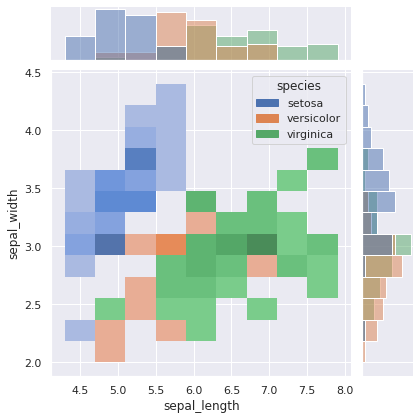
jointplot() and JointGrid¶
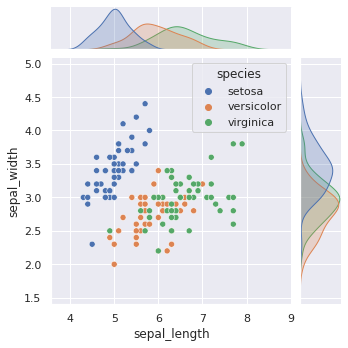
Das Erstellen von bivariaten Diagrammen ist mit jointplot() möglich. Diese Methode bietet eine einfache Schnittstelle für die JointGrid Klasse. Wenn mehr Flexibilität benötigt wird sollten wir JointGrid direkt verwenden.
jointplot() erzeugen einen Scatterplot mit KDE Diagrammen.
sns.jointplot(x="sepal_length", y="sepal_width", data=iris_df, height=5, hue="species")
<seaborn.axisgrid.JointGrid at 0x7f7385416760>
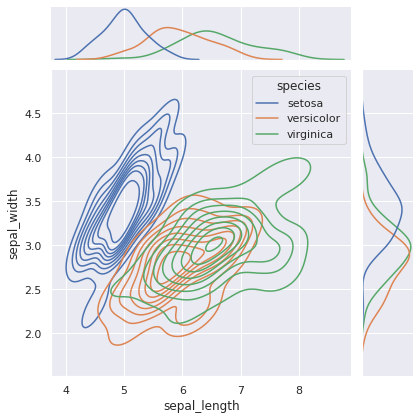
Statt einen Scatterplot können wir ein KDE Diagramm erzeugen.
sns.jointplot(x="sepal_length", y="sepal_width", data=iris_df, hue="species", kind="kde")
<seaborn.axisgrid.JointGrid at 0x7f7384b7bf40>
Statt einen Scatterplot können wir ein Histogramm erzeugen.
sns.jointplot(x='sepal_length',y='sepal_width', data=iris_df, hue="species", kind='hist')
<seaborn.axisgrid.JointGrid at 0x7f73876078b0>
Kategoriale Diagramme¶
seaborn hat eigne Diagramme für kategoriale Daten zu bieten. Wir wollen hier bekannte Methoden boxplot, violinplot und swarmplot anwenden.
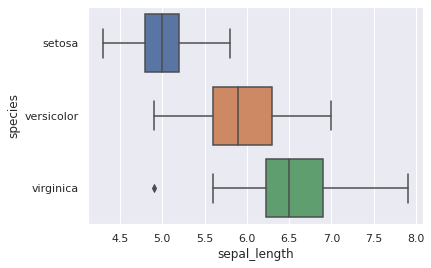
Boxplot¶
Der Box-Plot ist eines der bekanntesten statistischen Diagramme und fasst verschiedene Streuungs- und Lagemaße in einer Darstellung zusammen.
Kennwert |
Beschreibung |
Lage im Box-Plot |
|---|---|---|
Minimum |
Kleinster Datenwert des Datensatzes |
Ende eines Whiskers oder entferntester Ausreißer |
Unteres Quartil |
Die kleinsten 25 % der Datenwerte sind kleiner als dieser oder gleich diesem Kennwert |
Beginn der Box |
Median |
Die kleinsten 50 % der Datenwerte sind kleiner als dieser oder gleich diesem Kennwert |
Strich innerhald der Box |
Oberes Quartil |
Die kleinsten 75 % der Datenwerte sind kleiner als dieser oder gleich diesem Kennwert |
Ende der Box |
Maximum |
Größter Datenwert des Datensatzes |
Ende eines Whiskers oder entferntester Ausreißer |
Spannweite |
Gesamter Wertebereich des Datensatzes |
Länge des gesamten Box-Plots (inklusive Ausreißer) |
Interquartilsabstand |
Wertebereich, in dem sich die mittleren 50 % der Daten befinden. (Liegt zwischen dem 0,25- und dem 0,75-Quartil) |
Ausdehnung der Box |
sns.boxplot(y="species", x="sepal_length", data=iris_df)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
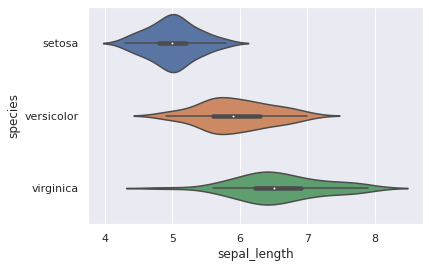
Violinplot¶
Der Violinplot ähnelt einem Boxplot. Der größte Unterschied ist, dass auf jeder Seite ein Kerneldichte-Plot (KDE) hinzugefügt wird.
Wichtige statistische Werte des Boxplots können auch im Violinplot erkannt werden. Im seaborn kann man den Median, Unteres Quartil, Oberes Quartil, Ausreißer erkennen.
sns.violinplot(y="species", x="sepal_length", data=iris_df)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
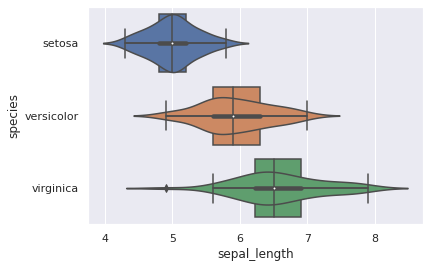
Für einen Vergleich können wir beide Plots übereinanderlegen. Wir sehen das die statistischen Werte übereinstimmen. Die KDE Schätzung ist aber an den Rändern eher unscharf.
sns.violinplot(y="species", x="sepal_length", data=iris_df)
sns.boxplot(y="species", x="sepal_length", data=iris_df)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
Stripplot¶
Der stripplot ist oft eine gute Ergänzung zu einem box- oder violinplot. Er gibt oft eine bessere visuelle Intuition wie Daten verteilt sind.
sns.stripplot(y="species", x="sepal_length", data=iris_df)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
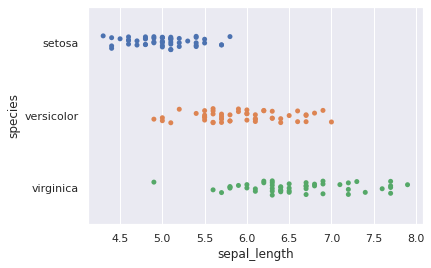
Wir können einen boxplot mit einem stripplot überzeichnen.
sns.boxplot(y="species", x="sepal_length", data=iris_df)
sns.stripplot(y="species", x="sepal_length", data=iris_df, color=".2", alpha=.5)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
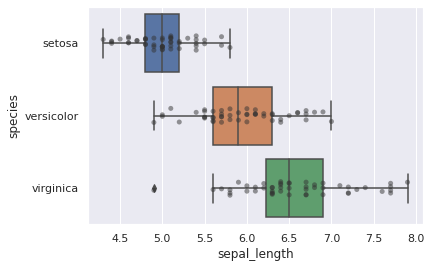
Wir können einen violinplot mit einem stripplot überzeichnen.
sns.violinplot(y="species", x="sepal_length", data=iris_df)
sns.stripplot(y="species", x="sepal_length", data=iris_df, color=".2", alpha=.5)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
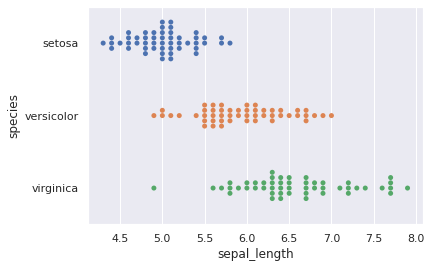
Swarmplot¶
Der swarmplot ist ähnlich wie der stripplot, jedoch überlappen sich Datenpunkte nicht. Die Dichte von Datenpunkte kann somit besser beurteilt werden.
sns.swarmplot(y="species", x="sepal_length", data=iris_df)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
Wir können einen boxplot mit einem swarmplot überzeichnen.
sns.boxplot(y="species", x="sepal_length", data=iris_df)
sns.swarmplot(y="species", x="sepal_length", data=iris_df, color=".2", alpha=.5)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
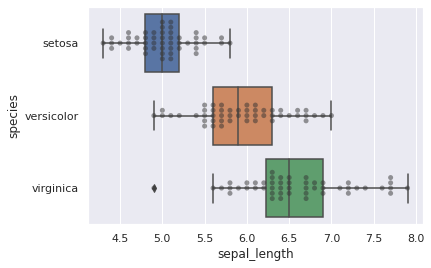
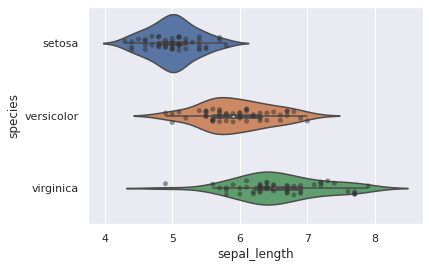
Wir können einen violinplot mit einem swarmplot überzeichnen.
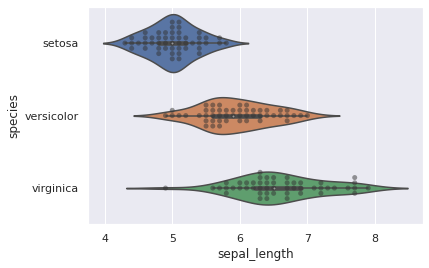
sns.violinplot(y="species", x="sepal_length", data=iris_df)
sns.swarmplot(y="species", x="sepal_length", data=iris_df, color=".2", alpha=.5)
<AxesSubplot:xlabel='sepal_length', ylabel='species'>
Weiter Schritte mit Seaborn¶
seaborn liefert eine Vielzahl an Datensätzen. Ein Datensatz der Ähnlichkeiten zum Iris Datensatz aufweist, ist der Penguins Datensatz.
Viele der gezeigten Plot-Techniken können dort wiederholt werden. Der Penguins Datensatz ist aber etwas komplizierte und die Datenbereinigung spielt dort eine Rolle.
penguins_df = sns.load_dataset("penguins")
penguins_df
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 339 | Gentoo | Biscoe | NaN | NaN | NaN | NaN | NaN |
| 340 | Gentoo | Biscoe | 46.8 | 14.3 | 215.0 | 4850.0 | Female |
| 341 | Gentoo | Biscoe | 50.4 | 15.7 | 222.0 | 5750.0 | Male |
| 342 | Gentoo | Biscoe | 45.2 | 14.8 | 212.0 | 5200.0 | Female |
| 343 | Gentoo | Biscoe | 49.9 | 16.1 | 213.0 | 5400.0 | Male |
344 rows × 7 columns
Fazit¶
seaborn liefert viele hilfreiche Methoden für das Erstellen von Diagrammen. Man kann seaborn sicher der Visual Analytics-Richtung zuweisen.
Durch das Untersuchen von beliebigen Daten mit pandas, matplotlib und seaborn ist das Erlernen dieser Bibliotheken einfach möglich. Der mathematische Aufwand hält sich erstmal in Grenzen.